What does “Joining” mean? | What fields should I use to join? | Can I join more than once? | How do I know I need to join? | Which dataset do I start with?
What does “Joining” mean?
Joining is a pretty technical term, but we can break it down. When you have data in two different datasets but need aspects from both, you can join the two tables together to get one bigger table. You can also think of this as how you get fields from one dataset into another one.

What fields should I use to join?
You should always use an ID field to join 2 datasets. While you can choose other types of fields, we strongly recommend you don’t. It can cause confusion if there are typos or if two values are the same (for example, two people have the same name, and you join using person_name). It is also important to note - just because the same ID is on two different datasets doesn’t mean you can join them. For example, tenant_id is on every dataset. Don’t ever use that to join. You can think about the larger pieces you’re trying to understand to determine what ID to use.
Example: You want to figure out how many people who had intakes now also have active cases. You have a few questions to ask yourself:
-
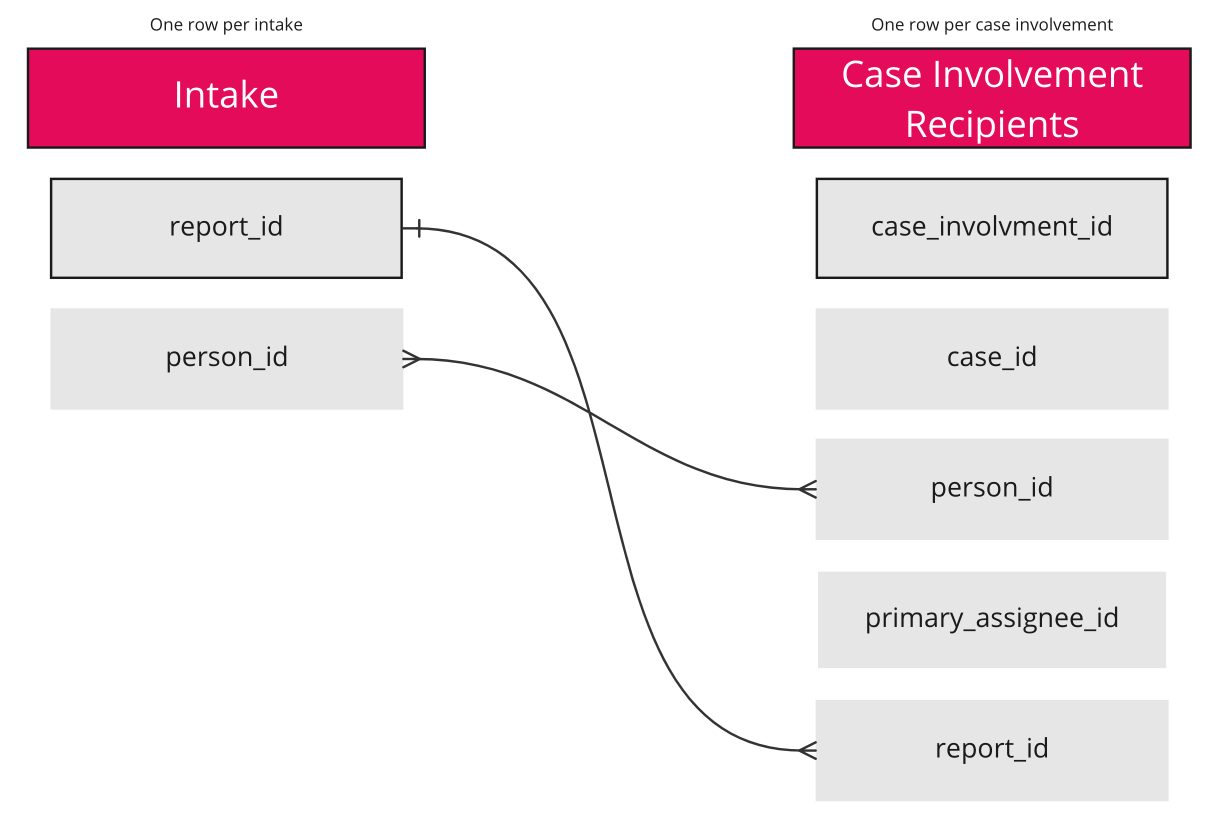
What are the IDs available to me in each dataset? Do they match?
-
You can see there are two IDs that are in both datasets.
-
-
Of the ones that match, which ones do I need?
This is the second hardest decision after you’ve identified which datasets you need and is the cause of most issues when it comes to joining datasets. The question you should try and ask yourself is, what are the bigger pieces of work I’m trying to join together? In this example, you want to know about intakes in relation to cases involvements. So, while you do have person_id and report_id in common between the datasets, you're focused on learning about which involvements are tied to which intakes.
![]() If you join on the person_id, your rows will split, so every intake report will be tied to all the cases where that person is listed - this will give you a table of incorrect information.
If you join on the person_id, your rows will split, so every intake report will be tied to all the cases where that person is listed - this will give you a table of incorrect information. ![]()

![]() When you join on case_id, you will get a table that shows you all the service enrollments and all the information about the cases associated with those service enrollments. This answers your main question about case information in relation to the service enrollments.
When you join on case_id, you will get a table that shows you all the service enrollments and all the information about the cases associated with those service enrollments. This answers your main question about case information in relation to the service enrollments. ![]()

Can I join more than once?
Yes. This is even necessary sometimes when you’re getting more complicated with your data pulls. It is advised that you save each time you join. Don’t forget to save your visualization but also save the entire dashboard.
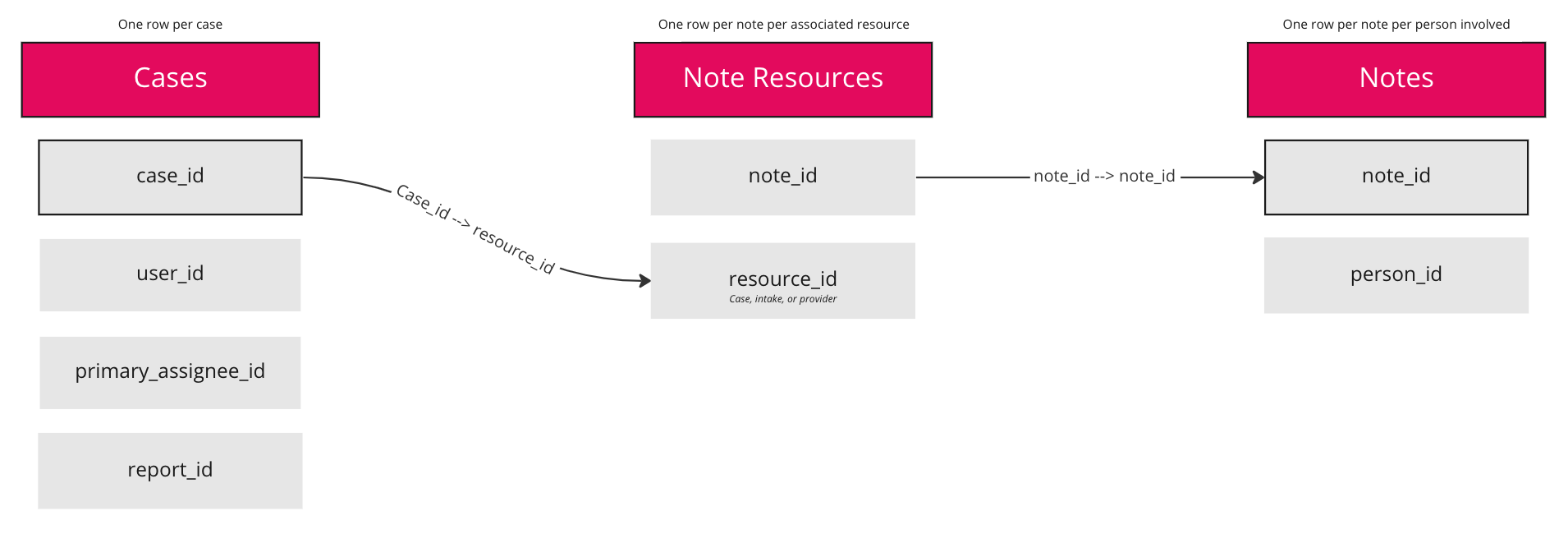
If you are trying to understand notes in relation to their units of work, for example, you want to know how many notes are assigned to all active cases, you’ll need to join twice.
-
In this example, you want to count information aggregated by case, so let’s start with the Cases dataset.
-
Join in the note_resources table using the case_id from cases and join it to the resource_id in the note_resources table. This table has a list of all the notes and what units of work they’re associated with.
-
Save your report.
-
Now go back in to edit and do another join from note_resources to Notes using note_id.
How do I know I need to join?
If you see fields in two datasets that you want to see together, then you need to join a dataset. So, you want to see all the people on active cases? That means you want to see People and Cases data together, so that’s a join!
Which dataset do I start with?
This is a great question and more important than you might think. We touched on this above, but you want to start with the dataset you want to aggregate toward. So, if you want to count the number of people assigned to each case, you're going to be counting people and summing those on cases, which means you start with cases.